

会議の録音や動画の字幕を、AIを使うことで自動で行うことができます。
もし、手作業で何時間もかけて字幕を作っている場合、大幅に作業時間を短縮できます。
この記事では、AI音声認識「Whisper」を使って、
WindowsのPCだけで文字起こし・字幕作成を行う方法を解説します。
WhisperはOpenAIが研究目的で公開しているオープンソースモデルのため、無料で利用できます。
Whisperとは?
OpenAI が公開した音声認識AIです。
実際に使ってみたところ、かなり精度が高かったため、実務レベルでも十分に使用できると思いました。
高精度であることの他にも以下の特徴があります。
- 無料で利用できる
- オフラインで使用可能
- 長時間の音声にも対応
- 動画から字幕(srt)も作成可能
- 翻訳字幕も作成可能
ここから先は、実際に動かすための具体的な手順を解説します。
この手順を完了すると、次のことが可能になります。
- 音声ファイル → テキスト生成(.txtファイル)
- 動画ファイル → 字幕生成(.srtファイル)
- 英語音声 → 日本語翻訳字幕を生成
- 長時間ファイルの処理
Pythonのインストール
WhisperはPythonという言語で動作します。
まずPythonをPCにインストールします。
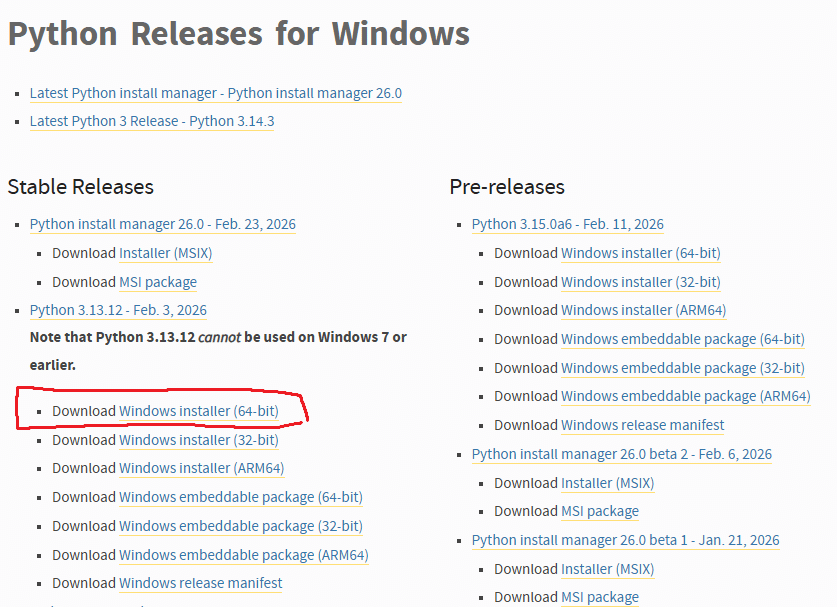
- Python公式サイトにアクセス
- 最新版(または推奨版)をダウンロード
- インストーラーを実行
※重要※
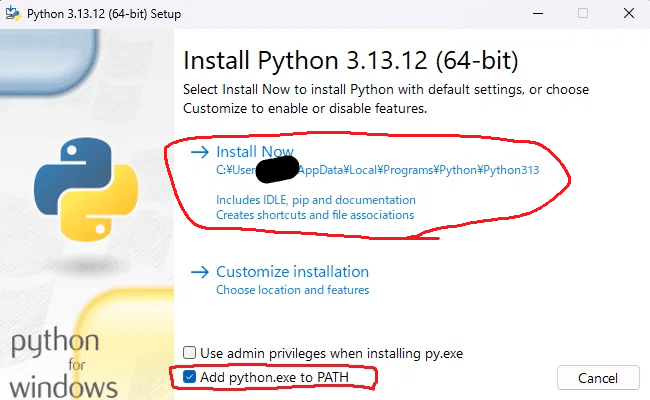
インストール画面で
Add Python.exe to PATHに必ずチェックを入れてください。
動作確認
コマンドプロンプトを開き、次を入力:
python --versionバージョン(例:Python 3.13.12)が表示されれば成功です。
ffmpeg の導入
Whisperは音声処理のために ffmpeg を使用します。
1.ffmpeg をダウンロード

2.ZIPを解凍する
→ダウンロードしたZIPを右クリックしてすべて展開
3.解凍したフォルダをわかりやすい場所に移動する
今回はC:\ffmpegに配置。
PATHに登録
- スタートメニューで「環境変数」と検索
- 「環境変数を編集」を開く
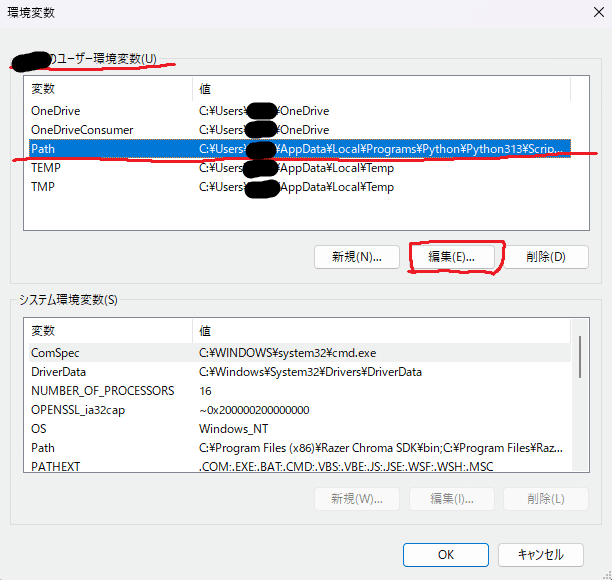
環境変数名の編集→新規でffmpegファイルのbinがある場所を入力
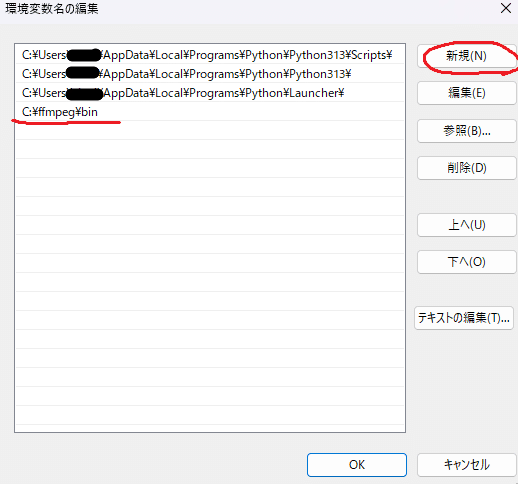
3.OKを押して環境変数画面を閉じる
動作確認
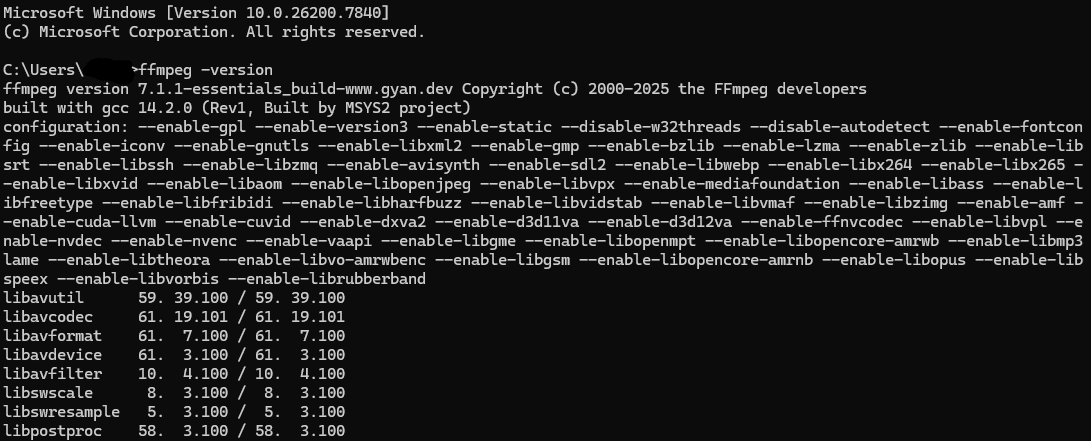
コマンドプロンプトを開いて以下を入力
ffmpeg -versionffmpeg version … とバージョンが表示されればOKです。
もし、
‘ffmpeg’ は内部コマンドまたは外部コマンドとして認識されていません
と表示された場合は、PATH設定のフォルダのパスが実際の場所となっているか確認。
その後、コマンドプロンプトの再起動をためしてみてください。
Whisperのインストール
コマンドプロンプトで以下を実行します。
pip install openai-whisper初回は数分かかります。
インストール完了後に以下を入力し、ヘルプが表示されれば成功です。
whisper --help文字起こしの実行
例として今回はデスクトップに作業用フォルダを作成します。
C:\Users\〇〇〇\Desktop\whisper_test
上記で作成したフォルダに、文字起こしをしたい音声ファイルを配置します。
例:audio.wav
そのフォルダでコマンドプロンプトを開きます。
- フォルダを開く
- 上のアドレスバーをクリック
- cmd と入力してEnter
以下のコマンドを実行。(CPUで処理を行っている場合は少し時間がかかります。)
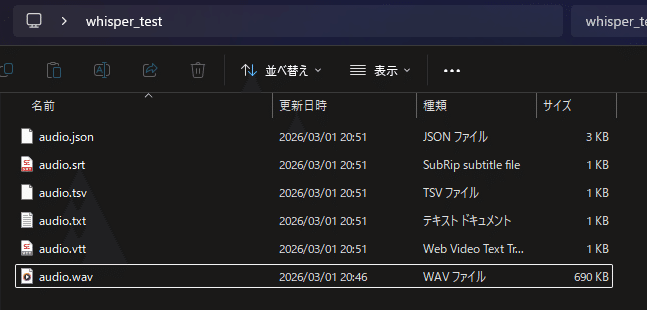
whisper audio.wav --language Japanese出力されるファイル
- audio.txt(文字起こし結果)
- audio.srt(字幕ファイル)
- audio.vtt(Web用字幕)
動画から字幕を作成
動画ファイル(mp4 など)でも同様に実行できます。
whisper video.mp4 --language Japanese音声が自動で抽出され、字幕が生成されます。
Whisperは公式READMEにある通り、音声読み込みにffmpegを使用しています。
そのため、ffmpegが対応している音声・動画形式を扱うことができます。
その他小ネタ集
モデルサイズについて
もし④で生成された字幕の精度がいまいちの場合、モデルサイズを指定することでより精度の高い字幕を作成できます。

例:
whisper sample.mp3 --model mediumwhisper sample.mp3 --model large※ただしモデルサイズを大きくするほど、字幕生成までの時間がかかります。
デフォルトでは small モデルが使用されます。
そのため、より精度を上げたい場合はmediumやlargeを指定することもできます。
※ただしCPU環境でlargeモデルを使うと、処理時間が実動画の数倍〜10倍以上になることもあるため、長時間動画では現実的ではありません。
日本語字幕の作成の場合、smallでもかなり高精度なため、まずはsmallで検証してみることをおすすめします。
GPUがある場合
CUDA対応していればWhisperは 自動でGPUを使用します。その場合、処理速度が大幅に向上します。
以下のコードを実行し、Trueと返ってくればWhisperは GPUを使用しています。
python -c "import torch; print(torch.cuda.is_available())"もしGPUを搭載しているのにFalseと返ってくる場合はGPUを使用するために別途設定が必要です。
(今後記事を書くかもです)
英語音声を日本語に翻訳
文字起こしと翻訳を同時に行うことができます。
以下を実行すると、英語 → 日本語の翻訳結果が出力されます。
whisper audio.mp3 --task translateよくあるエラーと対処法
■拡張子だけ変更している
audio.mp3 → audio.wav に名前だけ変更。
中身がmp3のままであるため、エラーになります。
■特殊コーデック
スマホ録音の一部形式でエラーが出ることがあります。
その場合はffmpegで変換する必要があります。
ffmpeg -i input.m4a output.wav■ ffmpeg not found
- ffmpegがインストールされていない可能性
- PATH設定を再確認
■ python が認識されない
- インストール時にAdd Python to PATHにチェックを入れ忘れている可能性
- Pythonの 再インストールを行う。
- インストール時に、Add Python to PATHにチェックを入れる
■ pip が使えない
python -m pip install --upgrade pipを実行
まとめ
Whisperを使えば、
高精度なAI文字起こしを無料・無制限で利用できます。
最初の環境構築だけ手間がありますが、
一度設定してしまえば、以降は簡単に使用できます。
AIを活用した作業効率化として、非常におすすめです。


コメント